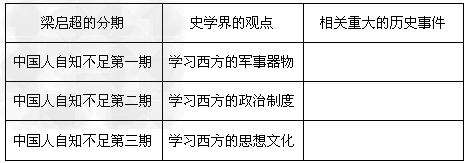
[说明]
已知包含头结点(不存储元素)的单链表元素已经按照非递减方式排序,函数compress(NODE*head)的功能是去掉其中重复的元素,使得链表中的元素互不相同。
在处理过程中,当元素重复出现时,保留元素第1次出现时所在的结点。
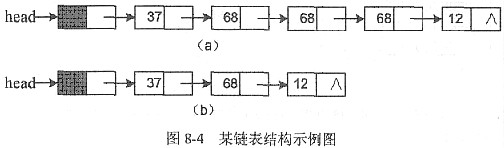
图8-4(a)、(b)是经函数compress()处理前后的链表结构示例图。
链表的结点类型定义如下。
typedef struct Node
int data;
struct Node *next;
NODE;
[C语言函数]
void compress (NODE *head)
NODE *ptr, *q, *s,*t;
ptr = head -> next;/* 取得第一个元素结点的指针*/
while (ptr && (1) )
q = ptr -> next;
while(q && (2) )/*处理重复元素*/
q = q -> next;
s = (3) ;
ptr -> next = q; /* 保留重复序列的第一个结点,将其余结点从链表中删除*/
while( s && (4) )/* 逐个释放被删除结点的空间*/
t = s-> next; free(s) ; s = t;
(5) = ptr -> next;
/* end of while */
/* end of compress */
参考答案:ptr->next
(2) q->data==ptr->data,或ptr->next->data==ptr->data,或其等价形式
(3) ptr->next
(4) s!=q
(5) ptr
解析:仔细通读题干的说明信息,以及所给出的整段C程序代码,试题要求去掉链表中的重复元素,使得链表中的元素互不相同,这就需要对链表进行查找和删除操作。
对于元素已经按照非递减方式排序的单链表,删除其中重复的元素,可以采用以下两种设计思路。
设计思路1:对于每一组重复元素,先找到其中的第1个结点,然后向后查找,直到出现一个相异元素时为止,此时保留重复元素的第1个结点,其余结点则从链表中删除。
单链表中每个结点的存储地址是存放在其前趋结点next域中的,而开始结点无前趋,故应设头指针head指向开始结点。结合图8-4所示的链表结构,在while外循环条件表达式中,需要表达的功能是:当前指针ptr所指向的结点有后继结点时才进入while循环体,因此(1)空缺处应填入ptr->next。
结合注释信息“处理重复元素”,根据前述算法思想,在第1个while内循环条件表达式中,当指针ptr所指结点的元素值与其后继结点的元素值相同时,则进入该while循环体继续扫描后继元素,直至出现一个相异元素时为止。因此(2)空缺处应填入表达式ptr->next->data==ptr->data或q->data==ptr->data。
(3) 空缺处应使用临时指针s暂时指向重复序列中需要删除的第1个结点的存储位置,以为后继逐个释放被删除结点的空间做好准备,即该空缺处应填入ptr->next。
由于退出第1个while内循环时,指针q指向了重复序列之后第1个相异元素,而此时指针ptr指向重复序列的第1个元素结点,因此使用语句“ptr->next=q;”可以保留重复序列的第1个结点,并将重复序列中的其余结点从链表中删除。
(4) 空缺处所处的第2个while内循环通过函数free()、临时指针s和临时指针t实现逐个释放重复序列中除第1个结点之外的其余结点存储空间的功能。当指针s还没到达指针q所指示的位置时,则进入第2个while内循环体执行相关结点存储空间的释放任务。因此,(4)空缺处应填入的表达式是s!=q。
(5) 空缺处应使指针ptr指向刚被删除的重复序列之后的第1个相异元素,为下一轮的遍历操作做准备,即该空缺处应填入ptr。
其对应的完整C代码如下。
void compress (NODE *head)
{ NODE *ptr,*q;
ptr = head -> next; /* 取得第一个元素结点的指针 */
while(ptr && ptr -> next) { /* 指针ptr指示出重复序列的第一个元素借点 */
q = ptr -> next;
while(q && ptr->next->data == ptr->data) [ /* 处理重复元素 */
q = q -> next; /* 继续扫描后继元素 */
s = ptp->next; /* 需要删除的第一个结点 */
ptr -> next = q; /* 保留重复序列的第一个结点,将其余结点从链表中删除 */
}
while(s && s !=q) { /* 逐个释放被删除结点的空间 */
t = s-> next; free[s); s = n;
}
ptr = ptr -> next; /* 令指针ptr指向刚被删除的重复序列之后第1个相异元素 */
}/* end of while */
}/* end of compress */
设计思路2:顺序地遍历链表。
仔细通读题干的说明信息,以及所给出的整段C程序代码,试题要求去掉链表中的重复元素;使得链表中的元素互不相同,这就需要对链表进行查找和删除操作。
对于元素已经按照非递减方式排序的单链表,删除其中重复的元素,可以顺序地遍历链表;对于逻辑上相邻的两个元素,比较它们是否相同,若相同,则删除后一个元素的结点,以此类推,直至表尾。单链表中每个结点的存储地址是存放在其前趋结点next域中,而开始结点无前趋,故应设头指针head指向开始结点。结合图所示的链表结构,要取得第1个元素结点的指针,则需要在(1)空缺处填入head->next。
在while外循环条件表达式中,应使指针ptr指示出重复序列的第一个元素结点,因此(2)空缺处应填入ptr。
结合注释信息“处理重复元素”,根据前述算法思想,在while外循环条件表达式中,当指针ptr所指结点的元素值与其后继结点的元素值相同时,则进入该while循环体进行相关的删除操作。因此(3)空缺处应填入表达式ptr->next->data==ptr->data或q->data==ptr->data。
在while内循环体中,使用语句“ptr->next=q->next;”将逻辑上相邻的两个相同元素的后一个结点从链表中删除。因此(4)空缺处应填入ptr->next。
(5) 空缺处应使指针ptr指向刚被删除的重复序列之后的第一个相异元素,为下一轮的遍历操作做准备,即该空缺处应填入ptr。