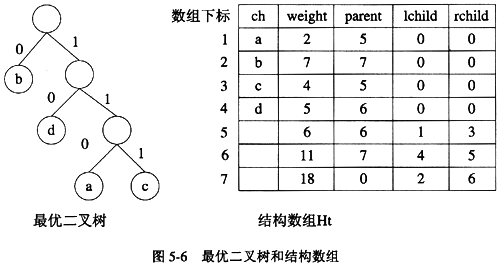
【预备知识】 ①对给定的字符集合及相应的权值,采用哈夫曼算法构造最优二叉树,并用结构数组存储最优二叉树。例如,给定字符集合{a,b,c,d}及其权值2、7、4、5,可构造如图5-6所示的最优二叉树和相应的结构数组Ht(数组元素Ht[0]不用)。
 结构数组Ht的类型定义如下: #define MAXLEAFNUM 20 struct node{ char ch;/*当前节点表示的字符,对于非叶子节点,此域不用*/ int weight; /*当前节点的权值*/ int parent; /*当前节点的父节点的下标,为0时表示无父节点*/ int lchild,rchild; /*当前节点的左、右孩子节点的下标,为0时表示无对应的孩子节点*/ }Ht[2*MAXLEAFNUM]; ②用“0”或“1”标识最优二叉树中分支的规则是:从一个节点进入其左(右)孩子节点,就用“0”(“1”)标识该分支(示例见图5-6)。 ③若用上述规则标识最优二叉树的每条分支后,从根节点开始到叶子节点为止,按经过分支的次序,将相应标识依次排列,可得到由“0”、“1”组成的一个序列,称此序列为该叶子节点的前缀编码。例如图5-6所示的叶子节点a、b、c、d的前缀编码分别是110、0、111、10。 【函数5-6说明】 函数void LeafCode(int root,int n)的功能是:采用非递归方法,遍历最优二叉树的全部叶子节点,为所有的叶子节点构造前缀编码。其中形参root为最优二叉树的根节点下标,形参n为叶子节点个数。 在构造过程中,将Ht[P].weight域用做被遍历节点的遍历状态标志。 【函数5-6】 char **Hc; void LeafCode(int root, int n) /*为最优二叉树中的n个叶子节点构造前缀编码,root是树的根节点下标*/ {int i,p=root,cdlen=0;char code[20];Hc=(char**)maloc((n+1)*sizeof(char*)); /*申请字符指针数组*/for(i=1;i<=p;++i) Ht[i].weight=0; /*遍历最优二叉树时用做被遍历节点的状态标志*/while(p){/*以非递归方法遍历最优二叉树,求树中每个叶子节点的编码*/ if(Ht[p].weight==0){/*向左*/ Ht[p].weight=1; if(Ht[p].lchild !=0){ p=Ht[p].lchild; code[cdlen++]=’0’; }else if(Ht[p].rchild==0){ /*若是叶子节点,则保存其前缀编码*/ Hc[p]=(char *)malloc((cdlen+1)*sizeof(char)); (1) ; strcpy(Hc[p],code); } }else if(Ht[p].weight==1)(/*向右*/ Ht[p].weight=2; if(Ht[p].rchild !=0){ p=Ht[p].rchild; code[edlen++]=’1’; } }else { /*Ht[p].weight==2,回退*/ Ht[p].weight=0; p= (2) ; (3) ; /*退回父节点*/ }}/*while结束*/ } 【函数5-7说明】 函数void Decode(char *buff,int root)的功能是:将前缀编码序列翻译成叶子节点的字符序列,并输出。其中形参root为最优二叉树的根节点下标,形参buff指向前缀编码序列。 【函数5-7】 void Decode(char *buff,int root) {int pre=root,p;while(*buff !=’\0’){ p=root; while(p !=0){/* 存在下标为p的节点*/ pre=p; if( (4) )p=Ht[p].lchild; /*进入左子树*/ else p=Ht[p].rchild; /*进入右子树*/ buff++; /*指向前缀编码序列的下一个字符*/ } (5) ; printf("%c",Ht[pre].ch);} }
结构数组Ht的类型定义如下: #define MAXLEAFNUM 20 struct node{ char ch;/*当前节点表示的字符,对于非叶子节点,此域不用*/ int weight; /*当前节点的权值*/ int parent; /*当前节点的父节点的下标,为0时表示无父节点*/ int lchild,rchild; /*当前节点的左、右孩子节点的下标,为0时表示无对应的孩子节点*/ }Ht[2*MAXLEAFNUM]; ②用“0”或“1”标识最优二叉树中分支的规则是:从一个节点进入其左(右)孩子节点,就用“0”(“1”)标识该分支(示例见图5-6)。 ③若用上述规则标识最优二叉树的每条分支后,从根节点开始到叶子节点为止,按经过分支的次序,将相应标识依次排列,可得到由“0”、“1”组成的一个序列,称此序列为该叶子节点的前缀编码。例如图5-6所示的叶子节点a、b、c、d的前缀编码分别是110、0、111、10。 【函数5-6说明】 函数void LeafCode(int root,int n)的功能是:采用非递归方法,遍历最优二叉树的全部叶子节点,为所有的叶子节点构造前缀编码。其中形参root为最优二叉树的根节点下标,形参n为叶子节点个数。 在构造过程中,将Ht[P].weight域用做被遍历节点的遍历状态标志。 【函数5-6】 char **Hc; void LeafCode(int root, int n) /*为最优二叉树中的n个叶子节点构造前缀编码,root是树的根节点下标*/ {int i,p=root,cdlen=0;char code[20];Hc=(char**)maloc((n+1)*sizeof(char*)); /*申请字符指针数组*/for(i=1;i<=p;++i) Ht[i].weight=0; /*遍历最优二叉树时用做被遍历节点的状态标志*/while(p){/*以非递归方法遍历最优二叉树,求树中每个叶子节点的编码*/ if(Ht[p].weight==0){/*向左*/ Ht[p].weight=1; if(Ht[p].lchild !=0){ p=Ht[p].lchild; code[cdlen++]=’0’; }else if(Ht[p].rchild==0){ /*若是叶子节点,则保存其前缀编码*/ Hc[p]=(char *)malloc((cdlen+1)*sizeof(char)); (1) ; strcpy(Hc[p],code); } }else if(Ht[p].weight==1)(/*向右*/ Ht[p].weight=2; if(Ht[p].rchild !=0){ p=Ht[p].rchild; code[edlen++]=’1’; } }else { /*Ht[p].weight==2,回退*/ Ht[p].weight=0; p= (2) ; (3) ; /*退回父节点*/ }}/*while结束*/ } 【函数5-7说明】 函数void Decode(char *buff,int root)的功能是:将前缀编码序列翻译成叶子节点的字符序列,并输出。其中形参root为最优二叉树的根节点下标,形参buff指向前缀编码序列。 【函数5-7】 void Decode(char *buff,int root) {int pre=root,p;while(*buff !=’\0’){ p=root; while(p !=0){/* 存在下标为p的节点*/ pre=p; if( (4) )p=Ht[p].lchild; /*进入左子树*/ else p=Ht[p].rchild; /*进入右子树*/ buff++; /*指向前缀编码序列的下一个字符*/ } (5) ; printf("%c",Ht[pre].ch);} }
参考答案:
解析:(1) [cdlen]=’\0’或code[cdlen]=0 (2) Ht[p].parent (3) --cdlen或等价形式 (4) *buff==’0’或等价形式 (5) buff--或等价形式
[分析]: 本题考查Huffman树最优前缀码的编码和译码。 函数5-6是用来为Huffman树的每个叶节点构造最优前缀码的,根据说明,实际上就是求从根节点到各叶节点的路径。程序对Huffman树进行前序遍历,将路径记录在code数组中,每碰到一个叶节点就输出从根节点到该叶节点的路径,即该叶节点的最优前缀码。 构造前缀码过程中,Ht[i].weight用做被遍历节点的遍历状态:为0表示节点i未被遍历过; 1表示已经被遍历过;2表示位于i节点的分支都被遍历,下步该遍历i节点的兄弟节点分支。故while语句下的3个if语句很明显分别对应这3种情况。 第一个if语句中,如果i节点没有被遍历过(Ht[i].weight为0),则应该先考查其是否有左子节点,有的话就表示其还不是叶节点,则下一个被遍历的节点为其左节点,同时将“0”字符保存到code数组中。如果没有左节点且没有右节点,表示其为叶节点,保存该路径。空 (1)之后的strcpy就是实现字符串拷贝,而字符串结束标志是“\0”,因此空(1)应填“code[cdlen]=’\0’”。这点在实际编程时亦需要特别注意。 第二个if语句中,考查Ht[i].weight等于1的情况,如果成立则表示i节点被遍历过(即已考查了其左节点),如果该节点没有右节点(Ht[i].rchild为0),应该回退到它的父节点,求下一个叶节点的编码;否则,记录字符“1”,继续遍历其右子树。 第三个if语句为回退到父节点,即指针p应指向i节点的父节点,同时路径存储数组code也应该回退一个字符(特别注意这一点)。故空(2)应填“Ht[i].parent”,空(3)应填“--cdlen”。 函数Decode的功能是将前缀码序列翻译成叶子节点的字符序列并输出。根据前缀编码在 Huffman树中表示的意义,程序依次扫描前缀码序列,根据扫描到的编码值遍历Huffman树:为0往左子树继续扫描,为1往右子树扫描。据注释,空(4)是进入左子树的条件,应该为“*buff==0”。 空(5)有比较大的难度。仔细分析while循环,会发现当while循环结束时,buff已经指向下一个叶子节点编码的第二个字符了。故空(5)应将编码字符指针回退一个字符,即应填“buff--”。