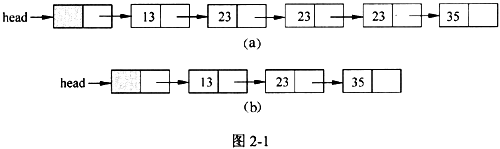
【说明】 已知包含头结点(不存储元素)的单链表的元素已经按照非递减方式排序,函数 compress(NODE*head)的功能是去掉其中重复的元素,使得链表中的元素互不相同。 处理过程中,当元素重复出现时,保留元素第一次出现所在的结点。 图2-1(a)、(b)是经函数compress()处理前后的链表结构示例图。
 链表的结点类型定义如下: typedef struct Node{ int data; struct Node *next; }NODE; 【C语言函数】 void compress(NODE *head) { NODE *ptr,*q; ptr= (1) ; /*取得第一个元素结点的指针*/ while( (2) && ptr->next) { q=ptr->next; while(q&& (3) ) { /*处理重复元素*/ (4) q->next;free(q);q=ptr->next; } (5) ptr->next; }/*end of while */ }/*end of compress*/
链表的结点类型定义如下: typedef struct Node{ int data; struct Node *next; }NODE; 【C语言函数】 void compress(NODE *head) { NODE *ptr,*q; ptr= (1) ; /*取得第一个元素结点的指针*/ while( (2) && ptr->next) { q=ptr->next; while(q&& (3) ) { /*处理重复元素*/ (4) q->next;free(q);q=ptr->next; } (5) ptr->next; }/*end of while */ }/*end of compress*/
参考答案:
解析:(1)head->next (2)ptr (3)q->data == ptr->data 或ptr->next->data==ptr->data,或其等价表示 (4)ptr->next (5)ptr
[分析]: 本题考查基本程序设计能力。 链表上的查找、插入和删除运算是常见的考点。本题要求去掉链表中的重复元素,使得链表中的元素互不相同,显然是对链表进行查找和删除操作。 对于元素已经按照非递减方式排序的单链表,删除其中重复的元素,可以采用两种思路。 1.顺序地遍历链表,对于逻辑上相邻的两个元素,比较它们是否相同,若相同,则删除后一个元素的结点,直到表尾。代码如下: ptr=head->next; /*取得第一个元素结点的指针*/ while (ptr && ptr->next){ /*指针ptr指示出重复序列的第一个元素结点*/ q=ptr->next; while(q && ptr->data==q->data) { /*处理重复元素*/ ptr->next=q->next; /*将结点从链表中删除*/ free(q); q=ptr->next; /*继续扫描后继元素*/ } ptr=ptr->next; } 2.对于每一组重复元素,先找到其中的第一个结点,然后向后查找,直到出现一个相异元素时为止,此时保留重复元素的第一个结点,其余结点则从链表中删除。 ptr=head->next; /*取得第一个元素结点的指针*/ while (ptr && ptr->next) { /*指针ptr指示出重复序列的第一个元素结点*/ q=ptr->next; while(q && ptr->data==q->data) /*查找重复元素*/ q=q->next; s=ptr->next; /*需要删除的第一个结点*/ ptr->next=q; /*保留重复序列的第一个结点,将其余结点从链表中删除*/ while (s && s!=q} { /*逐个释放被删除结点的空间*/ t = s->next; free(s); s = t; } ptr=ptr->next; } 题目中采用的是第一种思路。